转自:http://www.infoq.com/cn/news/2018/05/luojisiwei
方圆
曾先后在 Cisco,新浪微博从事基础架构研发工作。十多年一直专注于后端技术的研发,在消息通信,分布式存储等方向有着丰富的经验。个人技术兴趣广泛,主要专注 Go/Java/Python 等编程语言的发展,尤其是在云计算等前沿领域的应用。
一、改造的背景
得到最早的APP就是一个单体的PHP的应用,就是图中最大的黄色块,中间蓝色块代表不同模块。下面的黄色部分代表passport 和支付系统,这个是在做得到之前就存在的系统,因为公司早期有微信里的电商业务。
后来发现有一些业务逻辑并不需要从得到走,还有一些数据格式转换的工作也不需要跟业务完全耦合,所以加了一层PHP的网关就是下图看到的V3那部分。但是这样做也有一些问题,PHP后端是FPM,一旦后端的接口响应较慢,就需要启动大量FPM保证并发访问,从而导致操作系统负载较高,从这一点上来说,使用PHP做这部分工作并不合适。
屋漏偏逢连夜雨
案例一:8/31大故障:2017年8月31日的时候,老板做活动,导致流量超过预期很多,系统挂了两个小时。
案例二:罗老师要跨年
每年罗老师都要跨年演讲,第一年是在优酷,有200多万人的在线观看,第二年是同时和优酷等视频网站再加上深圳卫视一起合作直播,2016年深圳卫视的收视率是地方第一。2017年的老板当时想要送东西,送东西的这个场景比较恐怖,二维码一放出来,就会有大量用户同时请求。
最恐怖的事情是,老板要送的东西8月31日的时候还没有,要在后面2个月期间把东西开发出来。一方面业务迭代不能停,一方面需要扛过跨年,所以就需要我们对业务系统进行改造。
改造目标
-
高性能:首先是性能要高,如果你单台机器跑几十QPS,那么堆机器也很难满足要求。
-
服务化:服务化实际上在故障之前就已经开始了,并且由于我们不同的业务团队已经在负责不同的业务,实际上也是需要服务化继续做下去。
-
资源拆分隔离:随着服务化过程,就需要对资源进行拆分,需要每个服务提供相应的接口,服务之间不能直接访问其他服务的数据库或者缓存。
-
高可用:当时定的目标是99.9的可用性。
Go的好处很多,最重要的还是对PHP程序员来说,上手更容易,而且性能好很多
二、改造的过程
首先有一个系统架构图
对于系统改造来说,首先需要知道,系统需要改成什么样子。因此我们需要一个架构的蓝图。上面就是我们的架构蓝图。首先需要的是一个统一对外的API GATEWAY,图中最上层的黄色部分。 中间淡紫色的部分是对外的业务服务。浅绿色部分是基础资源服务,比如音频文稿信息,加密服务。下面红色部分是支付和passport等公用服务,最右侧是一些通用的框架和中间件。最下层是一些基础设施。
我们的框架跟基础设施的完善和系统重构是交织进行的,不是说一开始就有一个完全没问题的设计,随着业务的改造,会有很多新的功能加进来。
框架和基础设施完善
我不讲应用系统怎么拆分,因为每个公司业务系统都不一样,我讲一下我们在框架和中间件这部分事情。
API gateway
API gateway是我们和陈皓(著名的左耳朵耗子)团队合作研发的。他们团队对于我们成功跨年帮助很大,在此先感谢一下。
目的:
-
限流
API gateway主要的目的就是限流,改造过程当中,我们线上有400多个接口,经常加新功能。我们可以保证新接口的性能,但是总有在改造过程中疏忽的老接口,通过API gateway限流可以保证在流量大的时候,老接口也有部分用户可用。
-
升级API
大部分的API升级都是跟客户端解决的,但是我们不太强制用户升级,导致线上老接口存在很长时间,我们需要在API gateway这一层做一些把新接口数据格式转成老接口数据格式的工作。
-
鉴权
在拆分服务之后,需要统一对接口进行鉴权和访问控制,业界的做法通常都是在网关这一层来做,我们也不例外。
接下来看一下API gateway的架构:
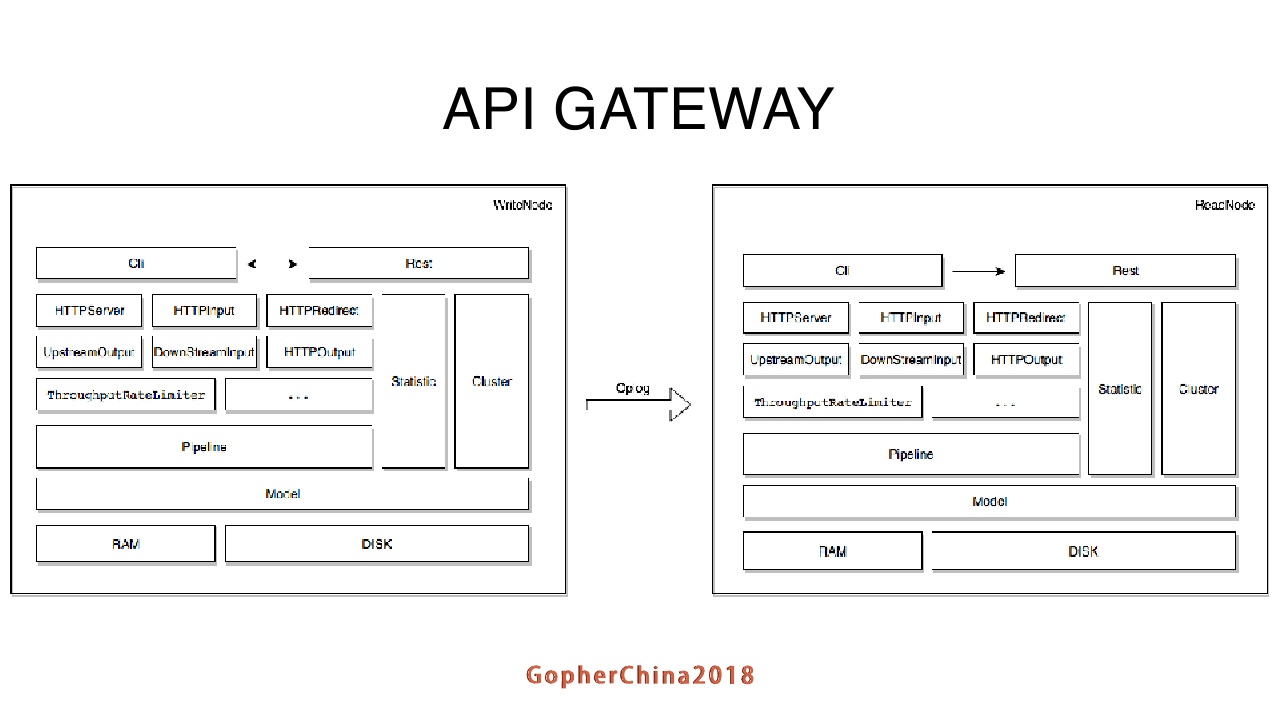
API gateway由一个write节点和多个read节点,节点之间通过gossip协议通信。每个节点最上层有一个CLI的命令行,可以用来调用Gateway的API。下层的HTTPServer等都是一个plugin,由多个plugin组成不同的pipeline来处理不同的请求。在后面我会介绍这个的设计。每个节点都有一个统计模块来做一些统计信息,这个统计信息主要是接口平均响应时间,QPS等。修改配置之后,write节点会把配置信息同步到read节点上,并且通过model模块持久化到本地磁盘上。
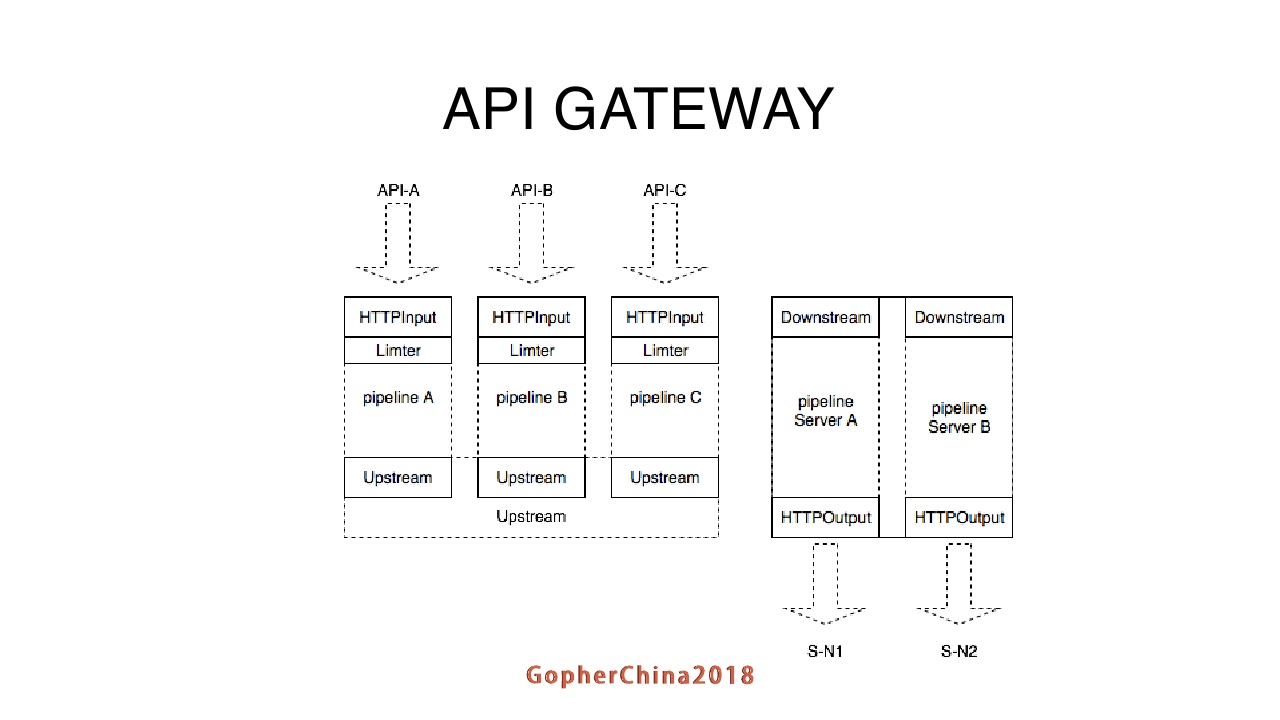
请求经过了两段pipeline,第一段pipeline基于请求的url。可以在不同的pipeline上面组合不同的plugin。假设一个接口不需要限流,只需要在接口的配置里头不加limiter plugin就可以了。第二段pipeline基于后端的Server配置,做一些负载均衡的工作。
接下来看整个API gateway启动的流程和调度方面:
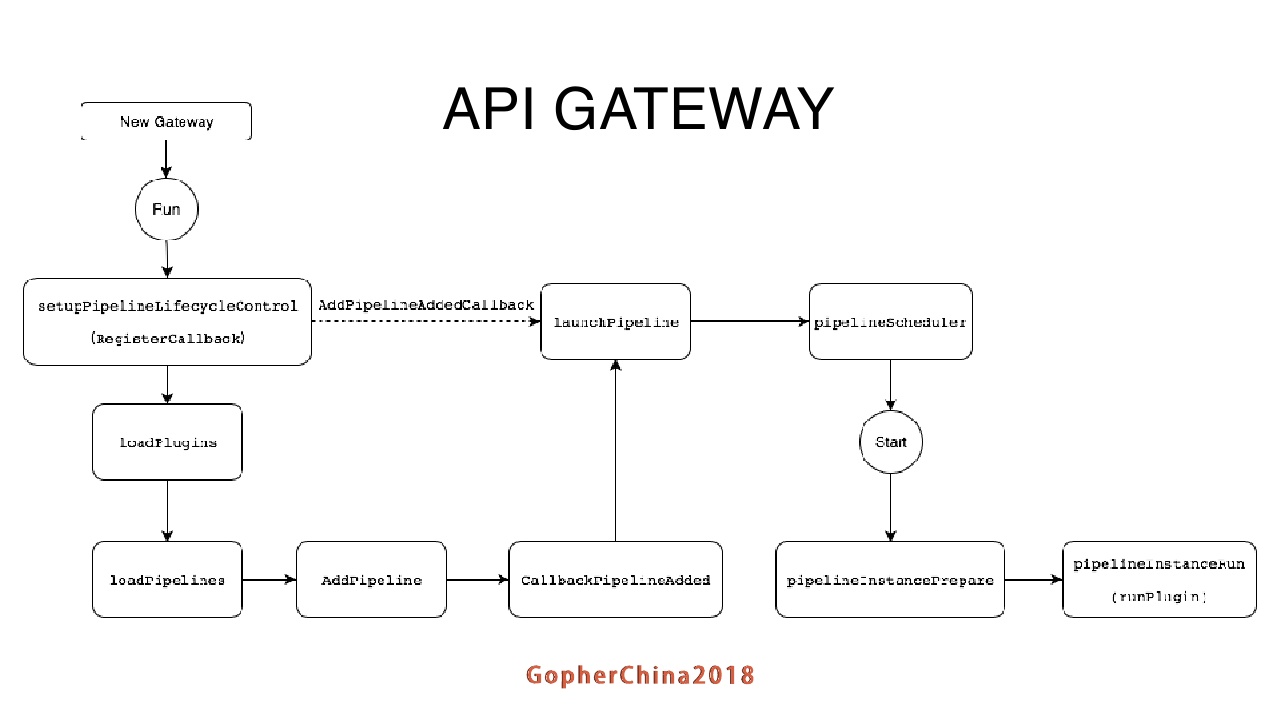
启动是比较简单的,去加载plugin,然后再去加载相应的配置文件,根据配置文件把plugin和pipeline做对应。右上角的这个调度器分为静态调度和动态调度。静态调度是假设分配5个go routine来做处理,始终都有5个go routine来处理对应的请求。动态调度器是根据请求繁忙程度,在一个go routine最大值和最小值之间变化。
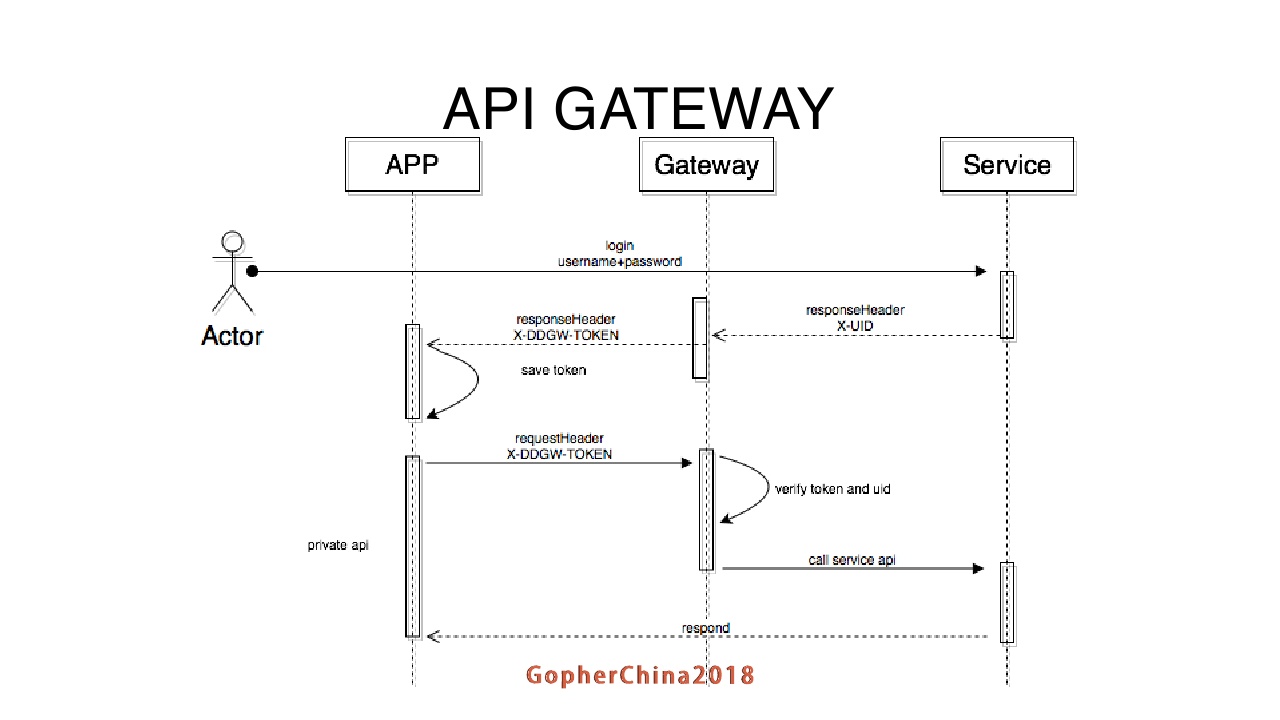
API gateway鉴权方面比较简单,客户端调用登录接口,passport会把token和userid,传到API gateway,API gateway再把相应的token传到这个APP端。客户端下次请求就拿token请求,如果token验证不过,就返回客户端。如果验证通过再调用后端不同的服务获取结果,最后返回结果给客户端。
最后再强调一下API gateway如何进行
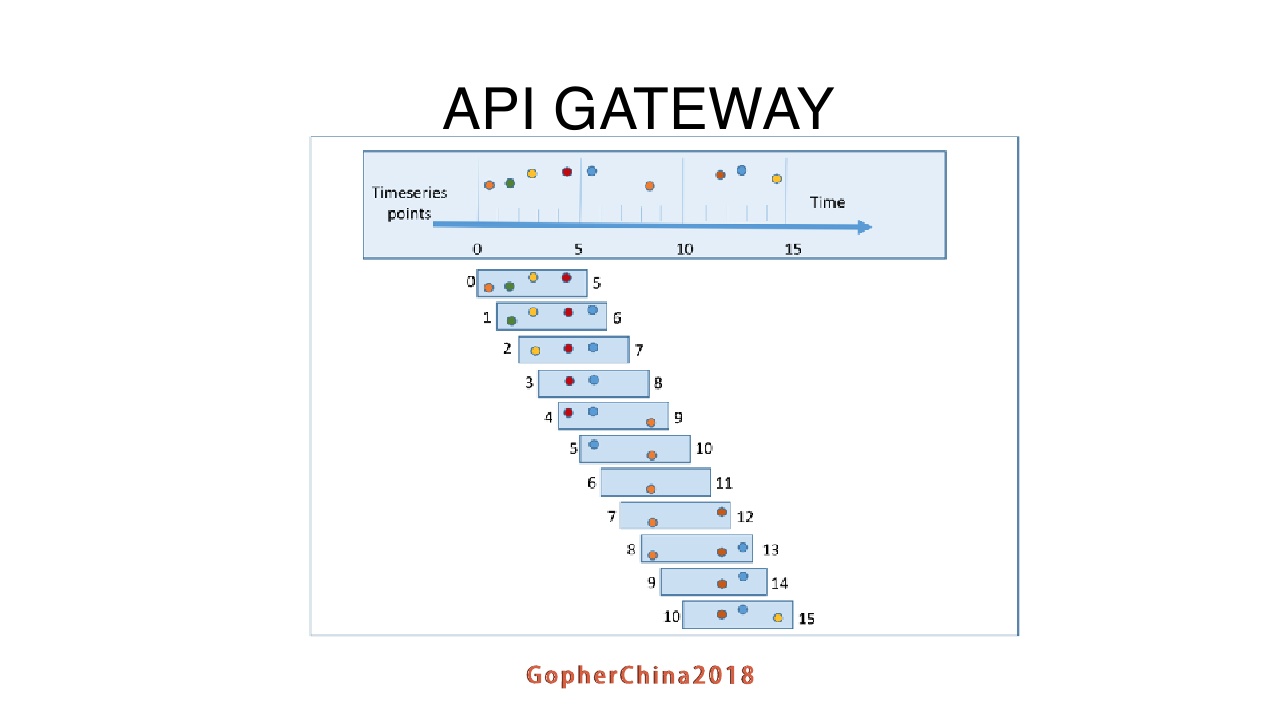
我们在API gateway里面引入两种限流的策略:
-
滑动窗口限流
为什么会根据滑动窗口限流呢?因为线上接口太多,我们也不知道到底是限100好200好还是限10000好,除非每一个都进行压测。用滑动窗口来统计一个时间窗口之内,响应时间,成功和失败的数量,根绝这个统计数据对下一个时间窗口是否要进行限流做判断。
-
QPS的限流
为什么还会留一个QPS的限流呢?因为要做活动,滑动窗口是一个时间窗口,做活动的时候,客户拿起手机扫二维码,流量瞬间就进来了,滑动窗口在这种情况下很难起到作用。
服务框架
目的:
-
简化应用开发
-
服务注册发现
-
方便配置管理
服务框架的常用架构
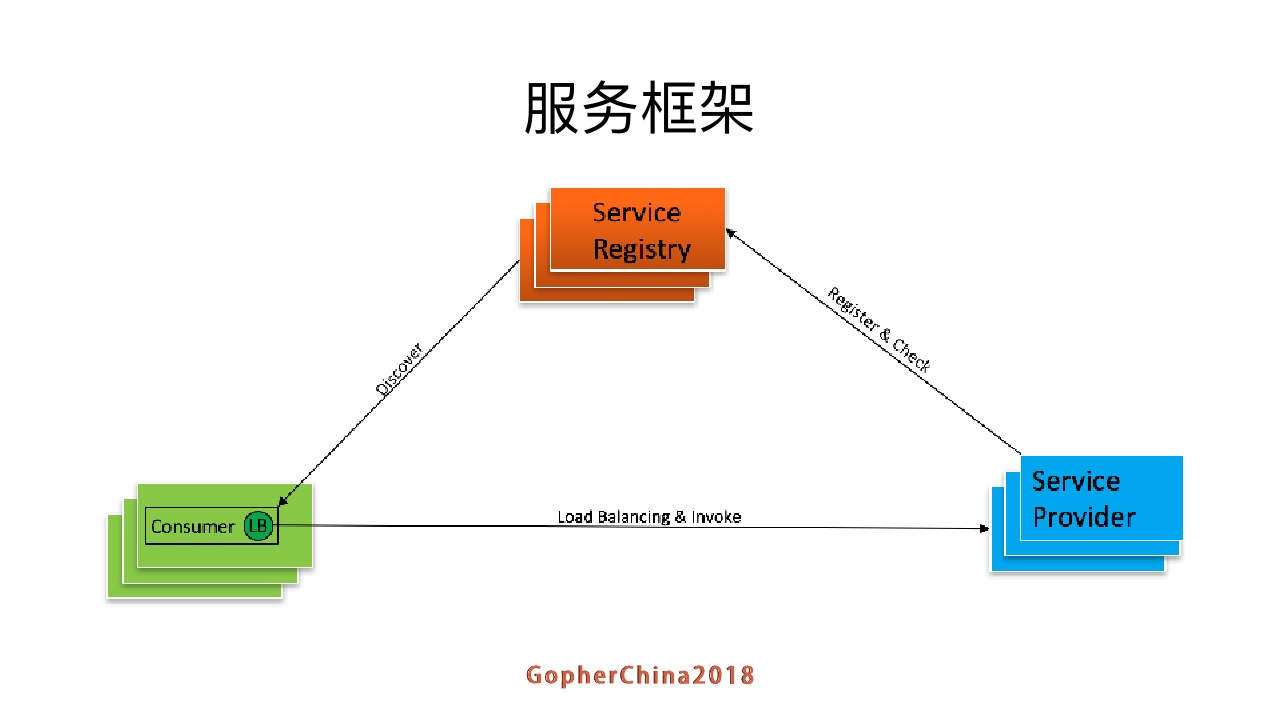
第一种方式是做成一个库,把相关功能编译进服务本身。这里有两个问题,第一个是我们兼容好几种语言,开发量比较大。还有一个是一旦客户端跟随服务调用方发布到生产环境中,后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。在业界来说,spring cloud,dubbo,motan都是用这样的机制。
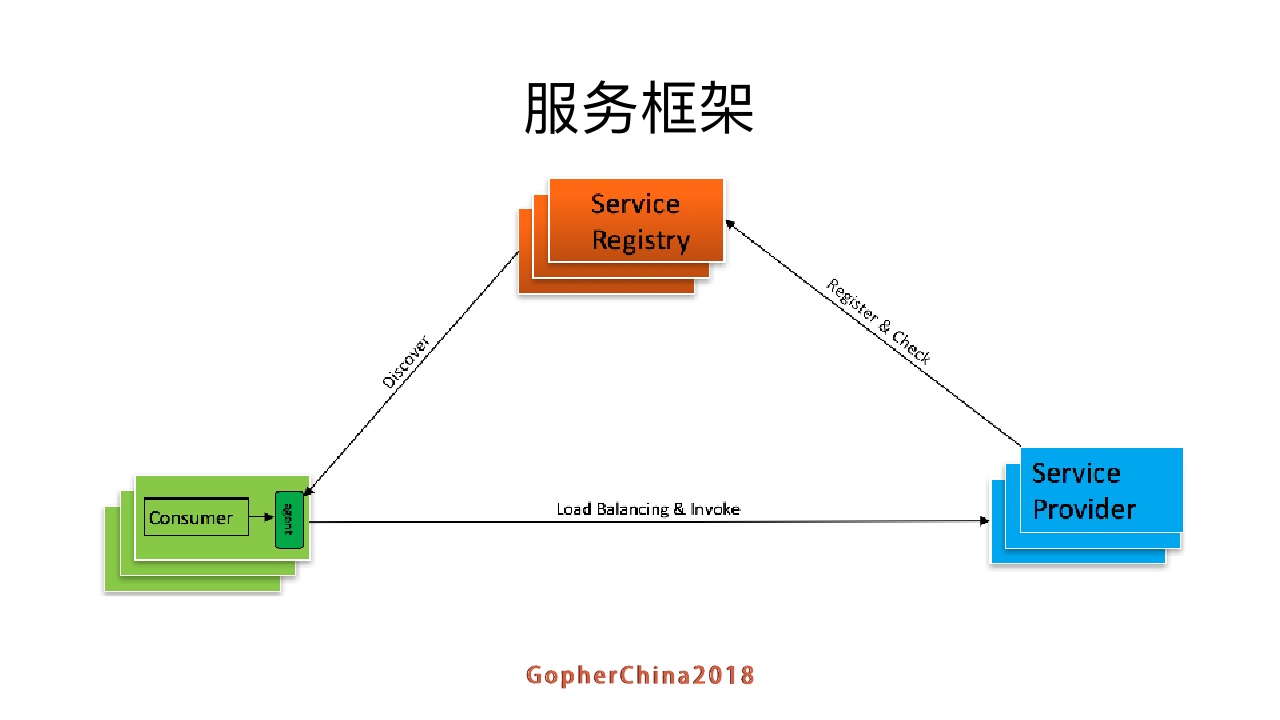
还有一种方案是把Lord Balancing的功能拿出来做成一个agent,跟consumer单独跑,每次consumer请求的时候是通过agent拿到Service Provder的地址,然后再调用Service Provder。
-
好处是简化了服务调用方,不需要为不同语言开发客户库,LB的升级不需要服务调用方改代码。
-
缺点也很明显,部署比较复杂;还有可用性检测会更麻烦一点,这个agent也可能会挂。如果agent挂掉,整个服务也要摘下来。
百度内部的BNS和Airbnb的SmartStack服务发现框架也是这种做法。由于我们内部语言较多,因此选择了第二种做法。
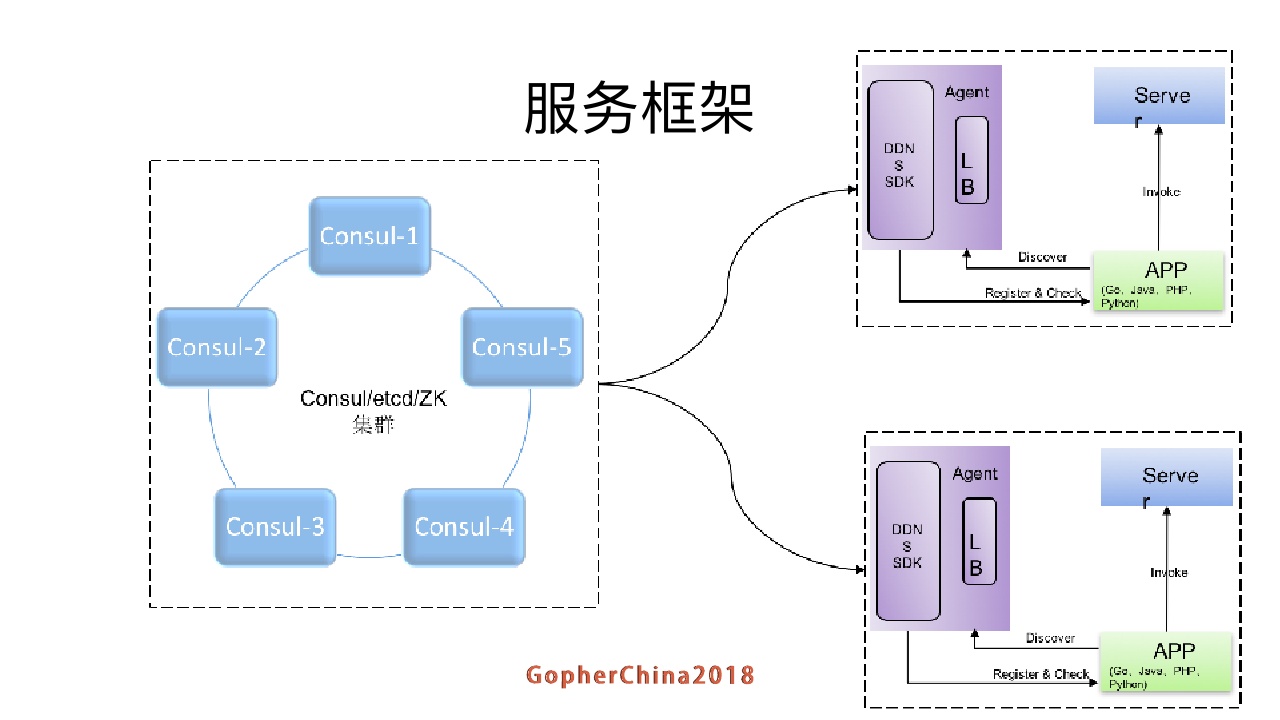
在Consul集群中,每个提供服务的节点上都要部署和运行Consul的agent,所有运行Consul agent节点的集合构成Consul Cluster。Consul agent有两种运行模式:
-
Server
-
Client
这里的Server和Client只是Consul集群层面的区分,与搭建在Cluster之上 的应用服务无关。以Server模式运行的Consul agent节点用于维护Consul集群的状态,官方建议每个Consul Cluster至少有3个或以上的运行在Server mode的Agent,Client节点不限。
Client和Server的角色在DDNS是没有严格区分的,请求服务时该服务就是Client,提供服务时候就是Server。
NNDS提供出来的是一个SDK可以很容易的集成和扩展为一个独立的服务并且集成更多的功能。采用agent方式,将在每一个服务器部署安装得到的agent,支持使用HTTP和grpc进行请求。
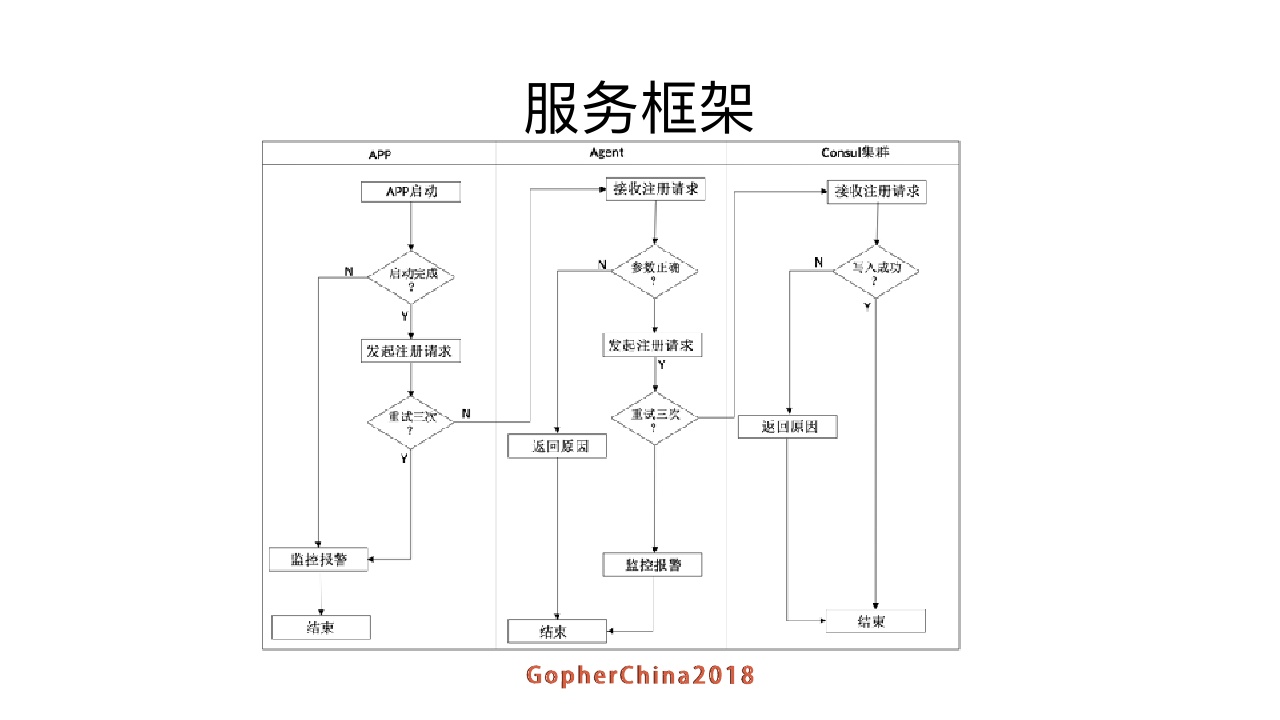
服务完成启动并可以可以对外提供服务之后,请求agent的接口v1/service/register将其注册的进入DDNS;
-
注册成功则其他客户端可以通过DDNS发现接口获取到该APP节点信息;
-
如果注册失败,APP会重复尝试重新注册,重试三次失败则报警;
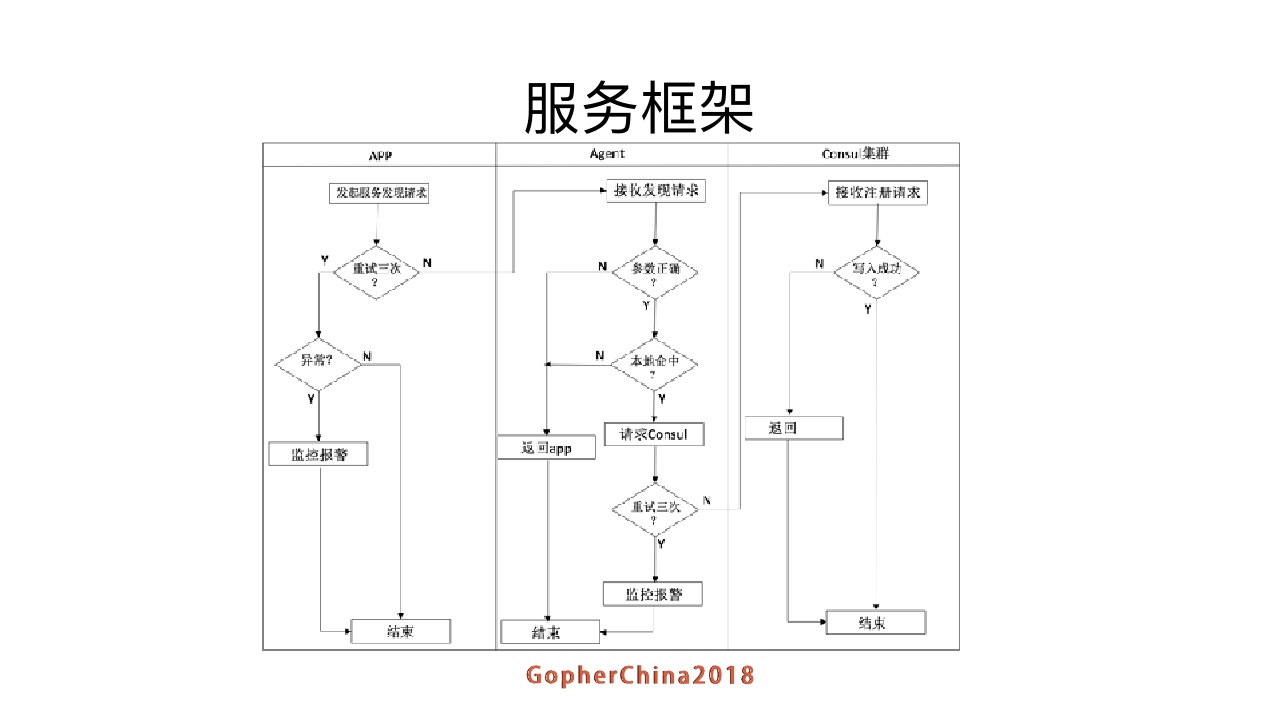
假设服务A需要请求服务B,服务名称为bbb,直接请求本机的agent接口v1/service/getservice,获取到bbb的服务节点信息。
对于agent而言,如果服务bbb是第一次被请求,则会请求Consul集群,获取到服务bbb的数据之后进行本地从cache并对服务bbb的节点进行watch监控,并定时更新本地的service信息;
如果获取失败,给出原因,如果是系统错误则报警;
这是服务框架基本的接口

这个就是客户端调用的封装,可以同时支持HTTP和JRTC,在这个之后我们还做了RBAC的权限控制,我们希望能调哪些服务都是可以做权限控制的。
多级缓存
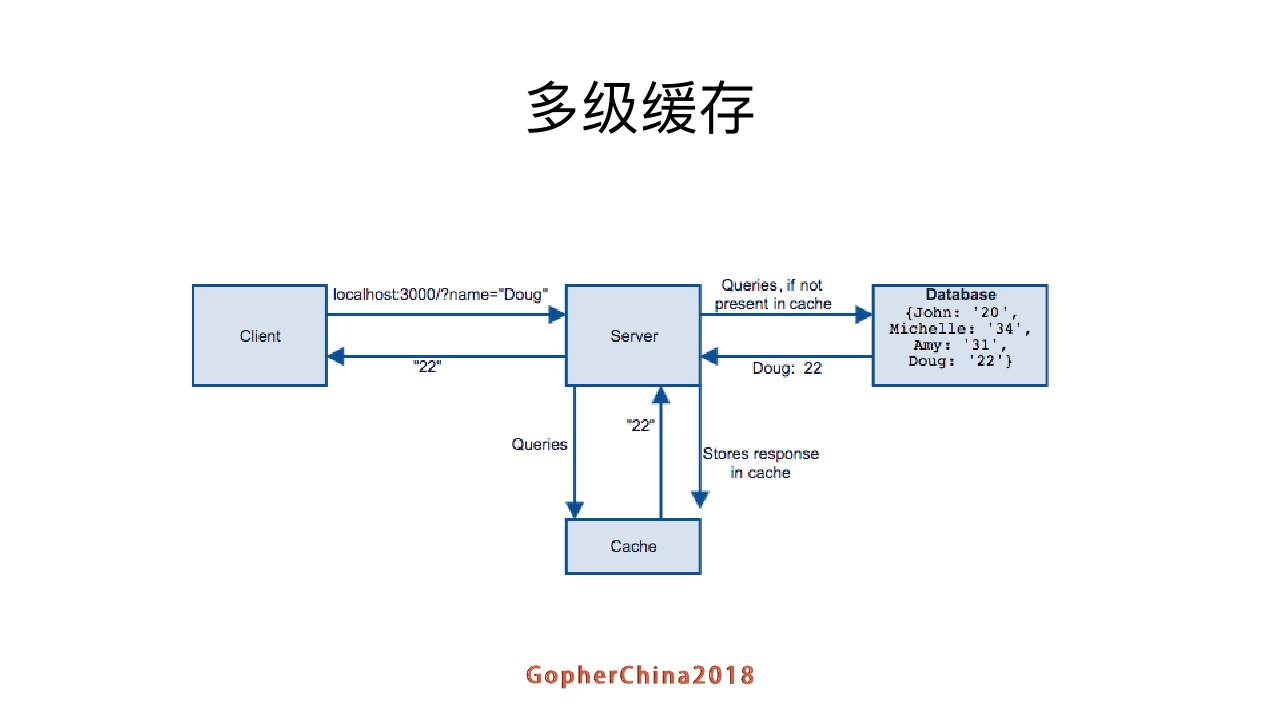
client请求到server,server先在缓存里找,找到就返回,没有就数据库找,如果找到就回设到缓存然后返回客户端。这里是一个比较简单的模型。只有一级cache,但是一级cache有可能不够用,比如说压测的时候我们发现,一个redis在我们的业务情况下支撑到接口的QPS就是一万左右,QPS高一点怎么办呢?我们引入多级缓存。
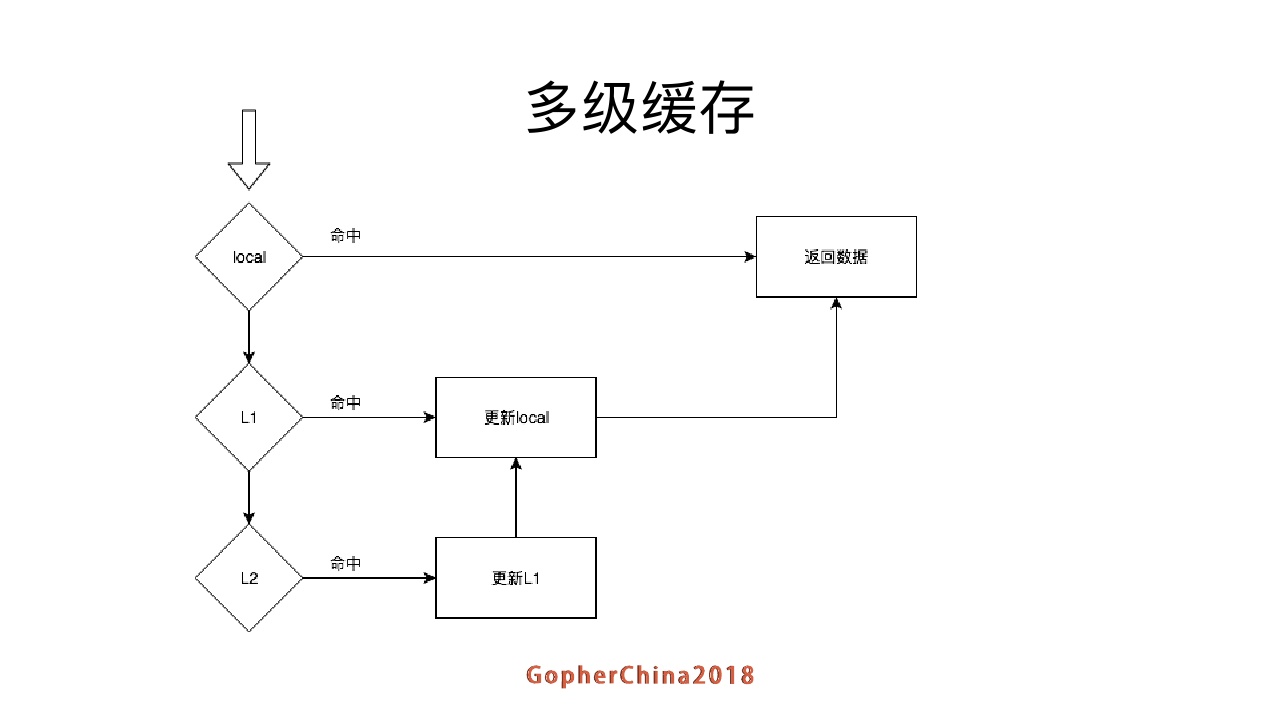
越靠近上面的缓存就越小,一级就是服务local cache,如果命中就返回数据,如果没有就去L1查,如果查到就更新local cache,并且返回数据。如果L1级也没有就去
L2级查,如果查到数据就更新L1 cache/local cache,并返回数据
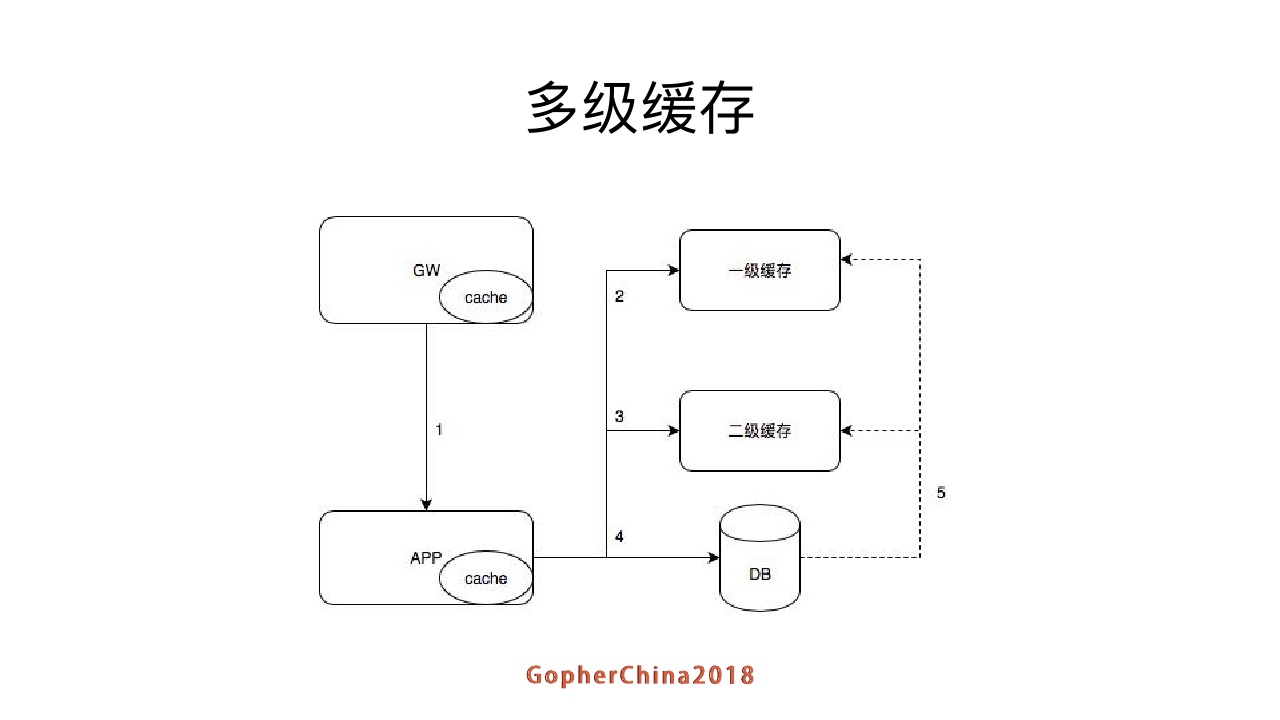
我们上面看到的是针对单条内容本身的缓存,在整个栈上来看,gateway也可以缓存一部分数据,不用请求透穿。这个5的虚线是什么意思呢?因为数据修改后需要更新,在应用层做有时候会有失败,所以读取数据库binlog来补漏,减少数据不一致的情况。

我一直觉得如果有泛型代码好写很多,没有泛型框架里面就要大量的反射来代替泛型。
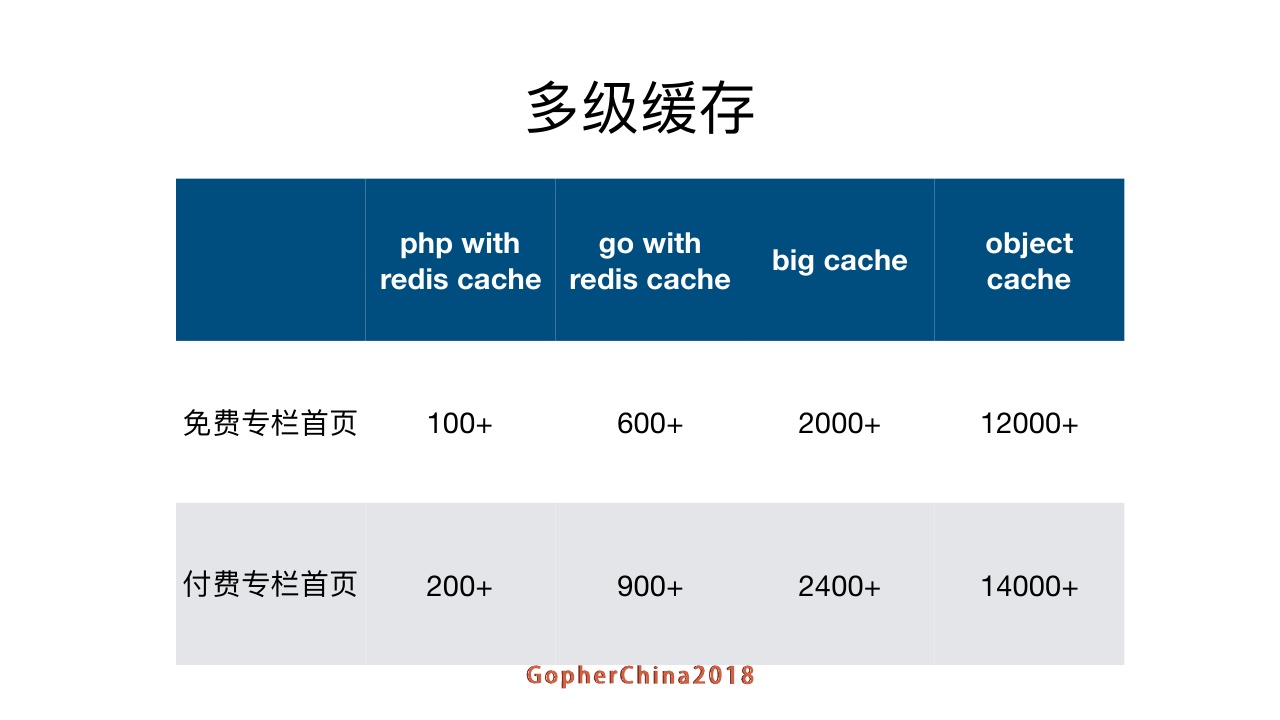
多级缓存开始加了之后整个性能的对比,最早PHP是一两百,改成Go之后,也不强多少,后面Go和big cache的大概到两千左右的,但是有一些问题,后面会讲当问题。后面基于对象的cache,把对象缓存起来,我们跑测试的机器是在八核,达到这样的结果还可以接受。
熔断降级
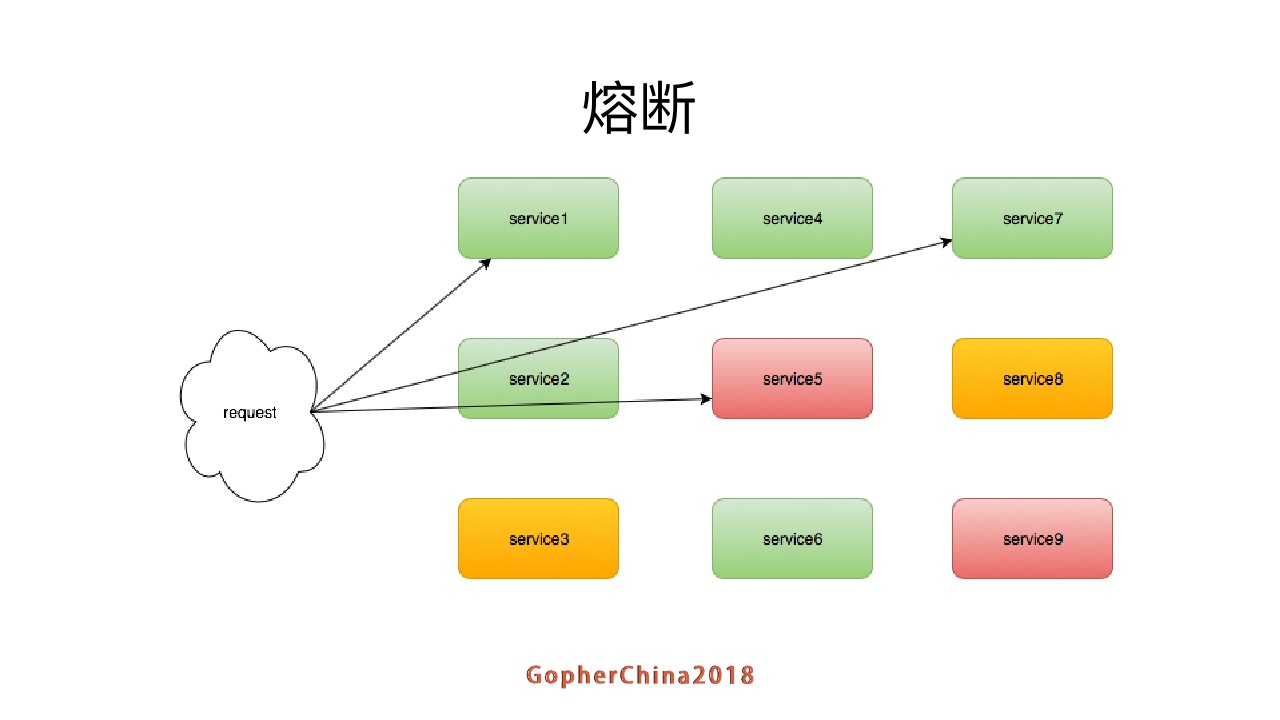
接口同时请求内部服务,service7、8、9不一样,service5是挂掉的状态,但是对外的服务还在每次调用,我们需要减少调用,让service5恢复过来。
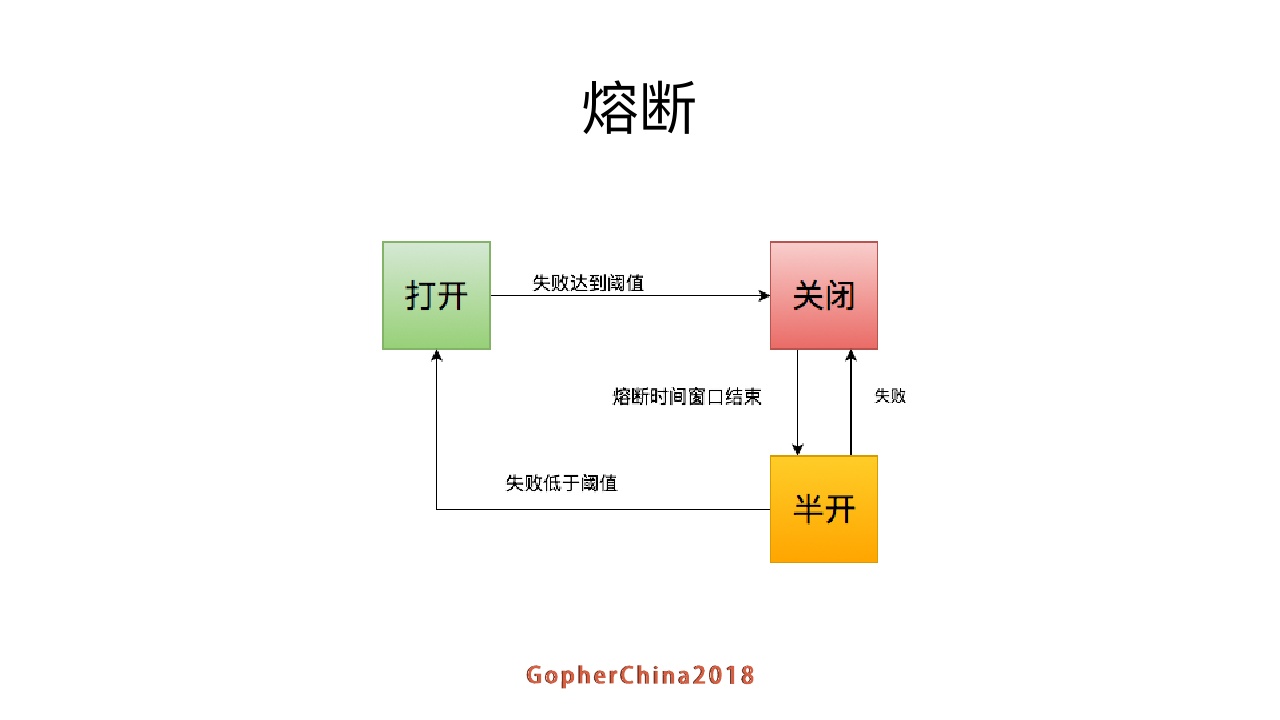
打开的状态下,失败达到一定的阈值就关起来,等熔断的窗口结束,达到一个半开的状态接受一部分的请求。如果失败的阈值很高就回到关闭的状态。这个统计的做法就是我们之前提到的滑动窗口算法。

这里是移植了JAVA hystrix的库,JAVA里面有很多做得很不错的框架和库,值得我们借鉴。
经验总结
通用基础库非常重要
刚才讲的性能提升部分,QPS 从600提升到12000,我们只用了一天,主要原因就在于我们通过基础库做了大量优化,而且基础库做的提升,所有服务都会受益。
善用工具
• generate + framework提升开发效率
• pprof+trace+go-torch确定性能问题
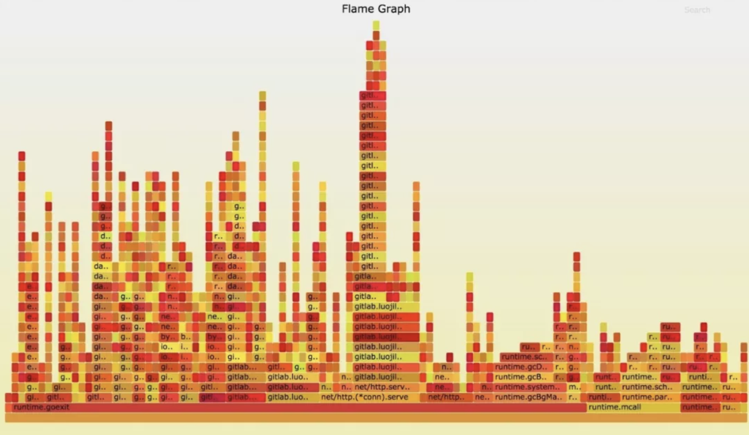
比如说我们大量的用generate + framework,通过generate和模板生成很多代码。查性能的时候,pprof+trace+go-torch可以帮你节省很多工作。Go-torch是做火焰图的,Go新版本已经内置了火焰图的功能。
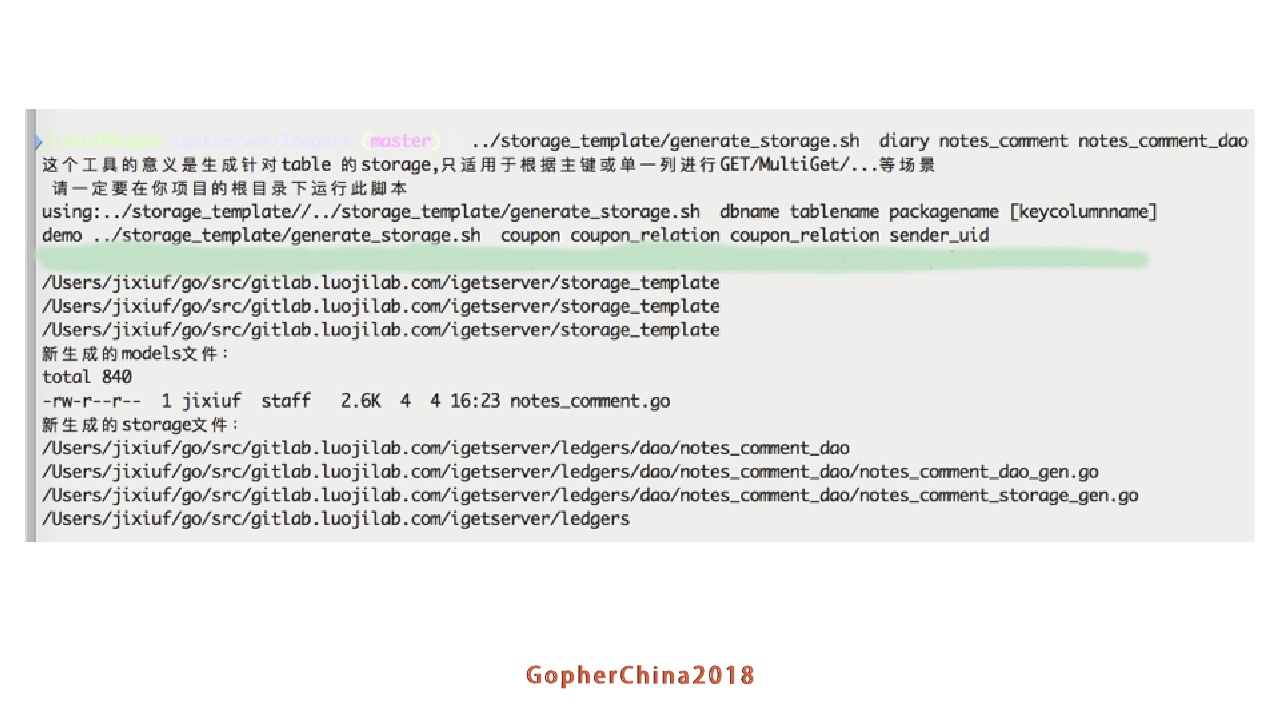
这是根据我们的表结构生成相应的数据库访问代码,多级缓存是把所有的访问都要抽象成K-V,K-LIST等访问模式,每次这么做的时候手动去写太繁琐,我们就做了一个工具,你用哪一个表,工具就生成好,你只需要把它组装一下。
定位性能问题的时候,火焰图一定要用
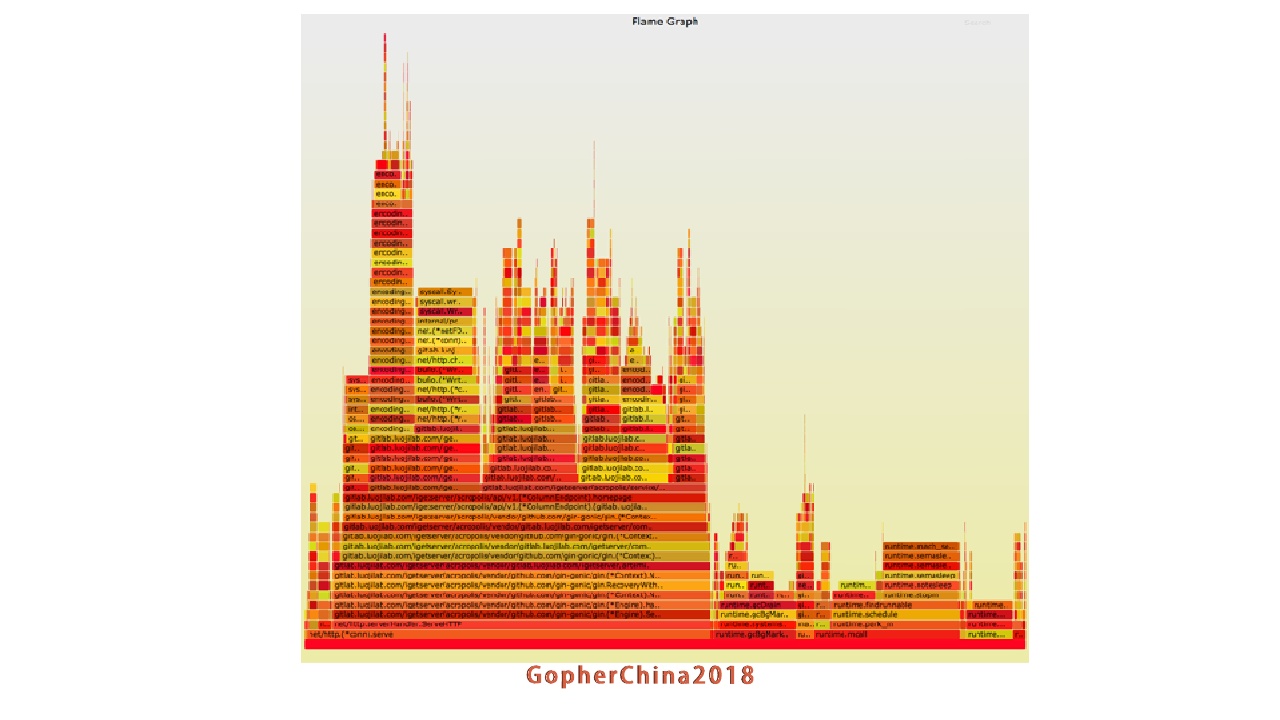
比如说定位性能问题就要看最长的地方在哪里,着力优化这个热点的code,压测的时候发现,大家600、900的火火焰图这里有问题,优化完成后如下图
其他经验总结
例如:
-
针对热点代码做优化
-
合理复用对象
-
尽量避免反射
-
合理的序列化和反序列化方式
接下来重点讲几个操作:
GC开销
举例来说我们之前有一个服务会从缓存里面拿到很多ID的list,数据是存成json格式[1,2,3]这样,发现json的序列化和反序列化性能开销非常大,基本上会占到50%以上的开销。
滴滴讲他们的json库,可以提升10倍性能,实际上在我们的场景下提升不了那么多,大概只能提升一倍,当然提升一倍也是很大的提升(因为你只用改一行代码就能提升这么多)。
其次json饭序列化导致的GC的问题也很厉害,最猛的时候能够达到20%CPU,即使是在Go的算法也做得很不错的情况下。
最终解决的办法就是在这里引入PB替代json。PB反序列化性能(在我们的情况下)确实比json好10倍,并且分配的临时对象少多了,从而也降低了GC开销。
为什么要避免反射呢?我们在本地建了local cache,缓存整个对象就要求你不能在缓存之外修改这个对象,但是实际业务上有这个需求。我们出现过这样的情况后就用反射来做deep copy。JAVA反射还可以用,原因是jvm会将反射代码生成JAVA代码,实际上调用的是生成的代码。
但是在Go里面不是,本来Go的性能是和C接近的,大量用了反射之后,性能就跟python接近额。后来我们就定义一个cloneable的接口,让程序员手动来做这个clone工作。
压力测试
我们主要用的就是ab和Siege,这两个通常是针对单个系统的压力测试。实际上用户在使用的过程当中,调用链上每一个地方都可能出现问题。所以在微服务的情况下,单个系统的压力测试,虽然很重要,但是不足以完全消除我们系统的所有问题。
举一个例子,跨年的时候罗老板要送东西,首先要领东西,领东西是一个接口,接下来通常用户会再刷一下已购列表看看在不在,最后再确认一下他领到的东西对不对。因此你需要对整个链路进行压测,不能只压测一下领取接口,这样可能是有问题的。假设你已购列表接口比较慢,用户领了以后就再刷一下看一看有没有,没有的情况下,一般用户会持续的刷,导致越慢的接口越容易成为瓶颈。因此需要合理的规划访问路径,对链路上的所有服务进行压测,不能只关注一个服务。
我们直接买了阿里云PTS的服务,他们做法就是在CDN节点上模拟请求,可以对整个访问路径进行模拟。
正在做什么
分库分表和分布式事务
选择一个数据库跟你公司相关的运维是相关的。分布式事务在我这里比较重要,我们有很多购买的环节,一旦拆了微服务之后,只要有一个地方错,就需要对整个进行回滚。我们现在的做法是手动控制,但是随着你后面的业务越来越多,不可能所有的都手动控制,这时就需要有一个分布式事务框架,所以我们现在基于TCC的方式正在做自己的分布式事务框架。
分库分表也是一个硬性的需求,我们在这里暂时没有上tidb的原因主要是DBA团队对tidb不熟悉。我们之前的分库分表也是程序员自己来处理,现在正在做一个框架能同时支持分库和分表,同时支持hash和range两种方式。
API gateway
API gateway上面有很多事情可以做,我们在熔断和降级做了一些事情。现在一些Service mesh做的很多事情是把很多工作放在内部API gateway上,是做控制的事情,实际上不应该是业务逻辑关心的事情。我们也在考虑怎么把API gateway和SM做结合。
APM
拆了微服务之后,最大的问题是不方便定位具体问题在哪里。我们有时候出问题,我叫好几个人看看各自负责的系统对不对,大家人肉看出问题的地方在哪,这是个比较蛋疼的做法。因入APM+tracing之后,就方便我们来追踪问题在哪里。
容器化
我们现在的线上环境,还是在用虚拟机。仿真环境和测试环境已经是容器,使用容器有很多好处,我就不一一列举了。这也是我们下半年要做的重点工作。
缓存服务化
我们现在有多级缓存的实现,但是多级缓存还是一个库的形式来实现的。如果把缓存抽出来,使用memcached或者redis的协议,抽出来成为一个独立的服务。后面的业务系统迭代的时候不用关心缓存本身的扩容缩容策略。
我今天分享的内容就到这儿,谢谢大家!
提问环节
Q:通过你的描述,我知道你以前有JAVA方面的经验,我们Go其实没有一个像JAVA spring cloud这样比较成熟的微服务的开箱即用的解决方案,现在让你重新做服务化转型这个事情,你会怎么选择?
方圆:让一群php程序员学JAVA比较麻烦,学习Go就比较简单。其次现在搞一个微服务框架,其实并没有那么难以接受。因为很多开源软件已经提供了对应的功能,所以要造的轮子其实没有那么多。
Q:你的分库分表框架里面有支持水平分库的情况吗?
方圆:支持。
Q:众所周知PHP是世界上最好的语言,你们转成Go,Go的开发效率比PHP(04:49:50)这两种情况。
方圆:我PHP学得不是太好,我自己写Go肯定比PHP快很多。我们团队来说,Go的开发效率比PHP略低,但是运行性能却好太多。
Q:重新选择一次技术选型,你是上来就选Go,还是从PHP再演化到Go?
方圆:我肯定是上来就选Go,我还是认为PHP做rest API没有啥优势。
本次方圆在ArchSummit的分享主要基于罗辑思维后端平台从其他语言转型至Go的整个实践过程,和大家分享转型的经历。涉及现有Go语言实现的服务框架技术栈选型,其中包括API Gateway,配置中心/服务注册发现,客户端负载均衡,分库分表,任务调度,多级缓存,熔断等多个方面。此外也会涉及到服务监控和容器化相关的工作,以及一些常见的痛点。最后对公司未来技术方向进行阐述。大纲如下:
为什么选择Go语言?
-
选择Go语言的原因:并发,性能
-
微服务架构
-
服务框架
-
API Gateway
-
配置中心/服务注册发现
-
client side lb
-
自动分库分表
-
分布式任务调度
-
多级缓存
-
熔断器
-
服务监控
-
容器化
碰见的问题:
-
Error处理和缺乏泛型
-
CPU使用分析
-
内存使用分析
-
公用代码库
未来需要的方向:
-
分布式事务
-
分布式追踪
-
Service Mesh